

Next.js is thought of as a frontend React framework. It provides server-side contribution, built-in routing process and many features related to performance. As Next.js supports the API routes, so it provides the backend and frontend to React, in the same package and setup.
We will dive into the process of setting up a GraphQL Server with Node.js inside your Next.js application in this blog. We’ll begin with the foundational steps, including API route setup, and explore essential concepts like CORS handling. You’ll also discover efficient data retrieval from Postgres using the Knex package, optimizing performance through Data Loader to prevent costly N+1 queries.
you can view source code here.
Setting Next.js
To set up Next.js run the command npx create-next-app. You can install npx by this command npm i -g npx , it installs it globally on your system.
An example can be used to setup Next.js with a GraphQL API:
npx create-next-app --example api-routes-graphql.
Addition of an API route
With Next.js setup, we’re going to add an API (server) route to our app. This is as easy as creating a file within the pages/api folder called graphql.js. For now, its contents will be:
export default (_req, res) => {
res.end("GraphQL!");
};What we want to produce
Now we want to try loading data efficiently from our Postgres database:
{
albums(first: 5) {
id
name
year
artist {
id
name
}
}
}
output:
{
"data": {
"albums": [
{
"id": "1",
"name": "Turn It Around",
"year": "2003",
"artist": {
"id": "1",
"name": "Comeback Kid"
}
},
{
"id": "2",
"name": "Wake the Dead",
"year": "2005",
"artist": {
"id": "1",
"name": "Comeback Kid"
}
}
]
}
}
Getting Started with GraphQL: Basic Setup
Setting up GraphQL involves four key steps:
1. Defining Types: Start by defining the types that describe the schema of your GraphQL server. These types define the structure of your data and how it can be queried or manipulated.
2. Creating Resolvers: Resolvers are functions responsible for responding to GraphQL queries or handling mutations (sudden changes to the data). They connect your GraphQL schema to the actual data sources and business logic.
3. Creating an Apollo Server: The Apollo Server is a crucial component that takes your schema and resolvers and turns them into a functioning GraphQL API server. It manages the execution of GraphQL queries and mutations.
4. Creating a Handler: In the context of Next.js API routes, you’ll create a handler to integrate your GraphQL server with your Next.js application. This handler facilitates communication between your Next.js API and the GraphQL server, allowing you to request data and handle responses in the application’s lifecycle.
Once these steps are complete, you can import the gql function from apollo-server-micro to define your GraphQL schema, making it ready for use in your application.
import { ApolloServer, gql } from "apollo-server-micro";
const typeDefs = gql`
type Query {
hello: String!
}
`;
As our schema is defined now , we can now write the code which will enable the server in answering the queries and sudden changes. This is called resolver and every field require function which will produce results. The resolver function gives result which align with the defined types.
The arguments received by resolver functions are:
- parent: it is ignored on query level.
- arguments: They would be passed in our resolver function and will allow us to access the field argument.
- context: it is a global state and tells about the authenticated user or the global instance and dataLoader.
const resolvers = {
Query: {
hello: (_parent, _args, _context) => "Hello!"
}
};
Passing typeDefs and resolvers to new instance of ApolloServer gets us up and running:
const apolloServer = new ApolloServer({
typeDefs,
resolvers,
context: () => {
return {};
}
});
By using apolloServer one can access a handler, helps in handling the request and response lifecycle. One more config which is needed to be exported, which stops the body of incoming HTTP requests from being parsed, and required for GraphQL to work correctly:
const handler = apolloServer.createHandler({ path: "/api/hello" });
export const config = {
api: {
bodyParser: false
}
};
export default handler;
Addition of CORS support
If we start or limit cross-origin requests by the use of CORS, we can add the micro-cors package to enable this:
import Cors from "micro-cors";
const cors = Cors({
allowMethods: ["POST", "OPTIONS"]
});
export default cors(handler);
In the above case the cross-origin HTTP method is limited to POST and OPTIONS. It changes the default export to have the handler pass to cors function.
Postgres , Knex with Dynamic data
Complex coding can be boring in many ways… now is the time to load from existing database. So for this a setup is needed to be installed and the required package is:
yarn add knex pg.
Now create a knexfile.js file, configure Knex so it helps in connecting to our database, The ENV variable is used for knowing the connection of database. You can have a look at the article setting up secrets. The local ENV variable looks like:
PG_CONNECTION_STRING=”postgres://leighhalliday@localhost:5432/next-graphql”:
// knexfile.js
module.exports = {
development: {
client: "postgresql",
connection: process.env.PG_CONNECTION_STRING,
migrations: {
tableName: "knex_migrations"
}
},
production: {
client: "postgresql",
connection: process.env.PG_CONNECTION_STRING,
migrations: {
tableName: "knex_migrations"
}
}
};
Now we can create database to set our tables. Empty files can be created with commands like yarn run knex migrate.
exports.up = function(knex) {
return knex.schema.createTable("artists", function(table) {
table.increments("id");
table.string("name", 255).notNullable();
table.string("url", 255).notNullable();
});
};
exports.down = function(knex) {
return knex.schema.dropTable("artists");
};
exports.up = function(knex) {
return knex.schema.createTable("albums", function(table) {
table.increments("id");
table.integer("artist_id").notNullable();
table.string("name", 255).notNullable();
table.string("year").notNullable();
table.index("artist_id");
table.index("name");
});
};
exports.down = function(knex) {
return knex.schema.dropTable("albums");
};
with the existing tables , run the following insert statements in Postico to set few dummy records:
INSERT INTO artists("name", "url") VALUES('Comeback Kid', 'http://comeback-kid.com/');
INSERT INTO albums("artist_id", "name", "year") VALUES(1, 'Turn It Around', '2003');
INSERT INTO albums("artist_id", "name", "year") VALUES(1, 'Wake the Dead', '2005');
The last step is creation of a connection to our DB within the graphql.js file.
import knex from "knex";
const db = knex({
client: "pg",
connection: process.env.PG_CONNECTION_STRING
});
New resolvers and definitions
Now remove the hello query and resolvers, and replace them with definitions for loading tables from the database:
const typeDefs = gql`
type Query {
albums(first: Int = 25, skip: Int = 0): [Album!]!
}
type Artist {
id: ID!
name: String!
url: String!
albums(first: Int = 25, skip: Int = 0): [Album!]!
}
type Album {
id: ID!
name: String!
year: String!
artist: Artist!
}
`;
const resolvers = {
Query: {
albums: (_parent, args, _context) => {
return db
.select("*")
.from("albums")
.orderBy("year", "asc")
.limit(Math.min(args.first, 50))
.offset(args.skip);
}
},
Album: {
id: (album, _args, _context) => album.id,
artist: (album, _args, _context) => {
return db
.select("*")
.from("artists")
.where({ id: album.artist_id })
.first();
}
},
Artist: {
id: (artist, _args, _context) => artist.id,
albums: (artist, args, _context) => {
return db
.select("*")
.from("albums")
.where({ artist_id: artist.id })
.orderBy("year", "asc")
.limit(Math.min(args.first, 50))
.offset(args.skip);
}
}
};
Now we can see that every single field is not defined for the resolvers. it is going to simply read an attribute from an object and defining the resolver for that field can be avoided. The id resolver can also be removed .
DataLoader and Avoiding N+1 Queries
There is an unknown problem with the resolvers used . The SQL query needes to be run for every object or with additional number of queries. There is a great article great article on this problem which helps to resollve the queries.
The step used firstly involves defining of the loader. A loader is used to collect IDs for loading in a single batch.
import DataLoader from "dataloader";
const loader = {
artist: new DataLoader(ids =>
db
.table("artists")
.whereIn("id", ids)
.select()
.then(rows => ids.map(id => rows.find(row => row.id === id)))
)
};
loader is passed to our GraphQL resolvers, see below:
const apolloServer = new ApolloServer({
typeDefs,
resolvers,
context: () => {
return { loader };
}
});
It allows us to update the resolver to utilize the DataLoader:
const resolvers = {
//...
Album: {
id: (album, _args, _context) => album.id,
artist: (album, _args, { loader }) => {
return loader.artist.load(album.artist_id);
}
}
//...
};
The problem is solved as the end result shows a single query for database for loading all objects at once.. N+1 issue is resolved..
Failure of Monitor and production of slow GraphQL requests
GraphQL h some debugging features which debugs request and responses, without effecting the production app. If one can ensure request related to networks then third party services can be used. try LogRocket.

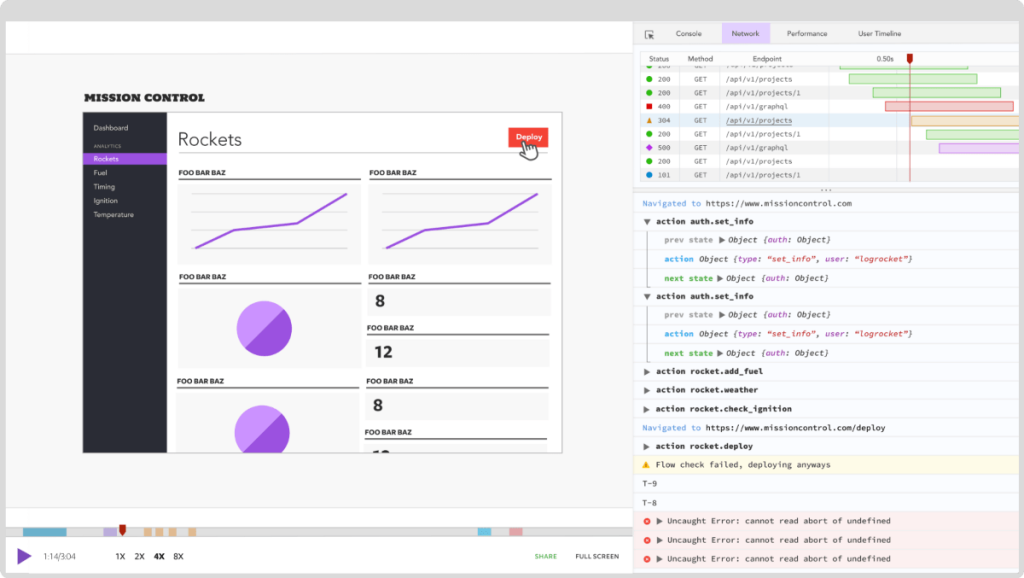
LogRocket serves as a powerful tool for web apps, functioning much like a DVR by meticulously recording every site activity. Beyond issue diagnosis, it excels at aggregating and reporting on problematic GraphQL requests, enabling a swift understanding of their root causes.
Additionally, LogRocket empowers users to track the Apollo client state, inspect GraphQL queries, and leverage instruments like key-value pairs. It goes further to capture essential baseline performance metrics, including page loading time, time to the first byte, and the identification of slow network requests. Furthermore, LogRocket logs actions and state for Redux, NgRx, and Vuex. With its robust capabilities, LogRocket offers a comprehensive solution for monitoring your GraphQL Server with Node.js. Start harnessing the power of LogRocket for free today.
Conclusion
In this article, we embarked on a journey to build a robust and efficient GraphQL Server with Node.js. We successfully implemented CORS support, seamlessly loaded data from Postgres, and effectively addressed N+1 performance issues using DataLoader. This accomplishment speaks volumes about the power of GraphQL and Node.js, showcasing what can be achieved in a single day’s effort.
Our next steps are equally exciting. We’re poised to enhance our GraphQL server by introducing mutations and incorporating authentication mechanisms. This will empower users to create and modify data with the necessary permissions, taking our application to the next level.
Furthermore, we’ve witnessed how Next.js, traditionally associated with frontend development, has evolved into a versatile framework with first-class support for server endpoints. It proves to be the ideal environment to host our GraphQL API, showcasing the seamless synergy between Next.js and GraphQL Server with Node.js. The journey continues as we explore the endless possibilities of this powerful stack.



Hey! Would you mind if I share your blog with my myspace group?
There’s a lot of people that I think would really appreciate your
content. Please let me know. Thanks