
🚀 U.S. Visa Approval Classification System
End-to-End MLOps Pipeline with CI/CD & Production Monitoring
Data Ingestion → Training → Deployment → Monitoring
Project Overview
Built an end-to-end MLOps pipeline for a U.S. Visa Approval Classification System, designed to take a model from data ingestion → training → deployment → monitoring with production-grade practices.
The project covers data ingestion and transformation, model training with hyperparameter optimization, and a repeatable pipeline structure for scalability and maintainability. It also supports training multiple models (XGBoost, CatBoost, RandomForest) and persisting artifacts for reproducible runs.
For deployment, the application is served via FastAPI (with a simple Jinja2 web UI and REST prediction endpoint), containerized with Docker, and deployed on AWS EC2. The Docker image is stored in AWS ECR, and deployments are automated through a GitHub Actions CI/CD pipeline. The project additionally includes model registry/versioning using AWS S3 and continuous evaluation/drift monitoring with Evidently AI, enabling ongoing reliability checks as data changes over time.
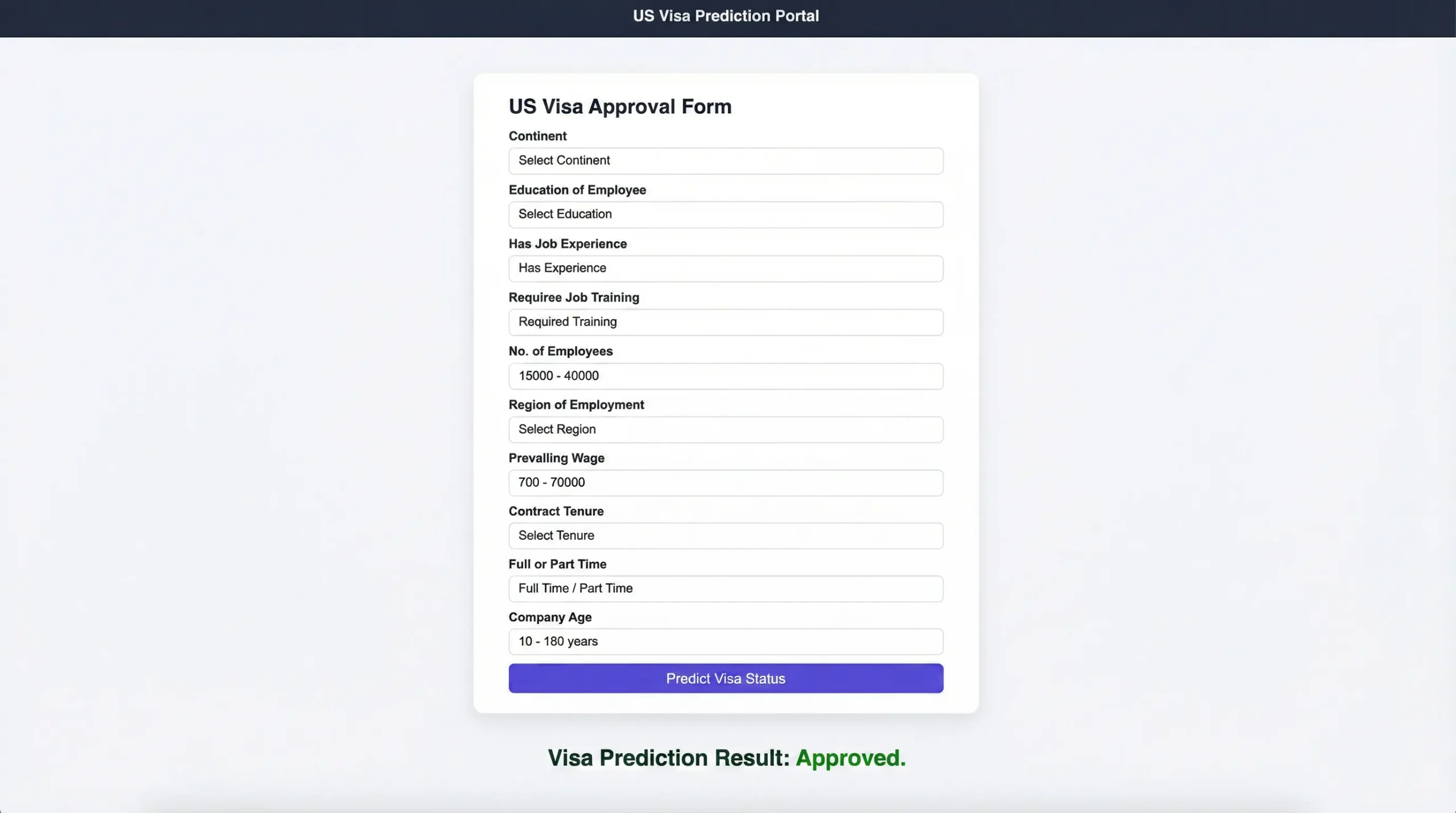
MLOps Pipeline Architecture
☁️ Cloud Infrastructure
AWS Deployment: EC2 for hosting, ECR for container registry, S3 for model artifacts, automated CI/CD via GitHub Actions
Key Features & Capabilities
Automated Data Pipeline
Modular data ingestion and transformation pipeline with validation checks, outlier detection, and feature engineering.
Multi-Model Training
Support for XGBoost, CatBoost, and RandomForest with hyperparameter optimization and cross-validation.
Containerized Deployment
Docker containerization with multi-stage builds for optimized image size and consistent deployment across environments.
FastAPI Service
High-performance REST API with Jinja2 web interface for real-time visa approval predictions and batch processing.
Model Versioning
AWS S3-based model registry with automatic versioning, metadata tracking, and rollback capabilities.
Drift Monitoring
Evidently AI integration for continuous model performance monitoring and data drift detection in production.
Technical Implementation
📥 Data Pipeline
- Data Ingestion: Automated data loading from multiple sources with schema validation
- Data Transformation: Feature engineering, encoding categorical variables, handling missing values
- Data Validation: Quality checks, outlier detection, data drift monitoring
- Artifact Management: Persistent storage of preprocessed data and transformers
🤖 Model Training & Evaluation
- Algorithm Support: XGBoost, CatBoost, RandomForest with configurable hyperparameters
- Hyperparameter Tuning: Grid search and randomized search for optimal model configuration
- Cross-Validation: Stratified K-fold validation for robust performance estimates
- Metrics Tracking: Accuracy, precision, recall, F1-score, ROC-AUC, confusion matrix
- Model Persistence: Serialized models stored in S3 with version control
🚀 Deployment Infrastructure
- API Framework: FastAPI with async request handling and auto-generated documentation
- Web Interface: Jinja2 templates for interactive prediction interface
- Containerization: Multi-stage Docker builds optimized for production
- Container Registry: AWS ECR for secure Docker image storage
- Cloud Hosting: AWS EC2 with auto-scaling and load balancing
🔄 CI/CD Pipeline
- GitHub Actions: Automated testing, building, and deployment workflows
- Automated Testing: Unit tests, integration tests, model validation tests
- Docker Build: Automatic image building and pushing to ECR on merge
- Zero-Downtime Deployment: Blue-green deployment strategy on AWS EC2
- Rollback Support: Automated rollback on deployment failure
Monitoring & Observability
📊 Model Performance Monitoring
- Real-time accuracy tracking
- Prediction distribution analysis
- Confusion matrix updates
- Performance degradation alerts
🔍 Data Drift Detection
- Feature distribution shifts
- Statistical drift tests (KS, Chi-square)
- Target variable drift monitoring
- Automated retraining triggers
⚡ System Health Monitoring
- API response time tracking
- Request throughput metrics
- Error rate monitoring
- Resource utilization (CPU, memory)
📈 Evidently AI Integration
- Automated drift reports
- Interactive HTML dashboards
- Historical performance comparison
- Model quality degradation alerts
Technology Stack
Key Achievements & Best Practices
- Production-Grade MLOps: End-to-end pipeline from data to deployment
- Automated CI/CD: Zero-touch deployments with GitHub Actions
- Model Reproducibility: Version-controlled models and artifacts in S3
- Scalable Architecture: Containerized services with cloud deployment
- Continuous Monitoring: Real-time drift detection and performance tracking
- Multi-Model Support: Flexible framework for different ML algorithms
- Modular Design: Reusable components for maintainability
- Automated Rollback: Safety mechanisms for deployment failures
View Project on GitHub
Complete source code, pipeline configurations, deployment scripts, and comprehensive documentation available on GitHub.
Need an MLOps Solution?
I build production-grade ML pipelines with automated training, deployment, and monitoring on AWS, GCP, and Azure.