My Expertise in Cloud & DevOps for AI
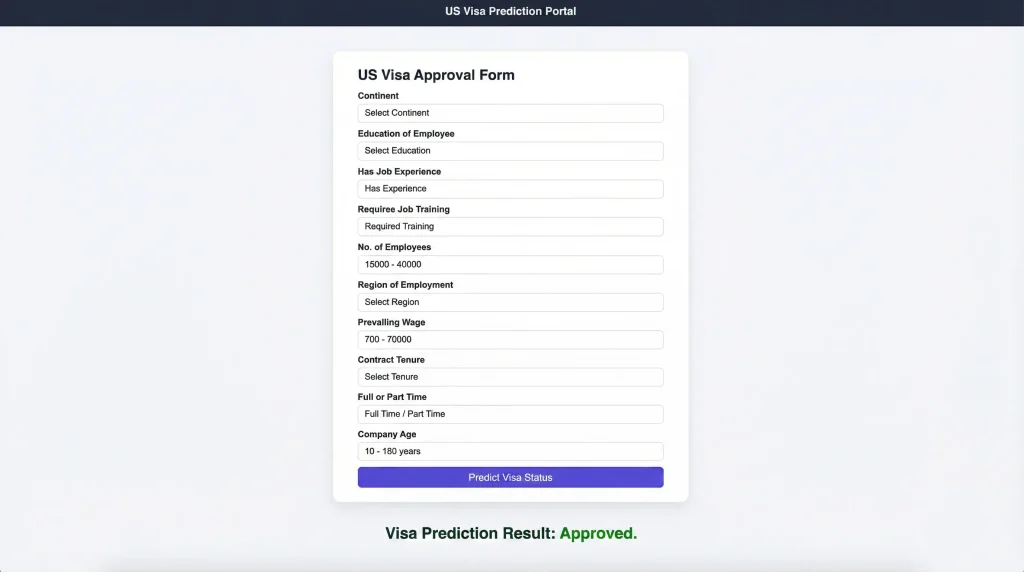
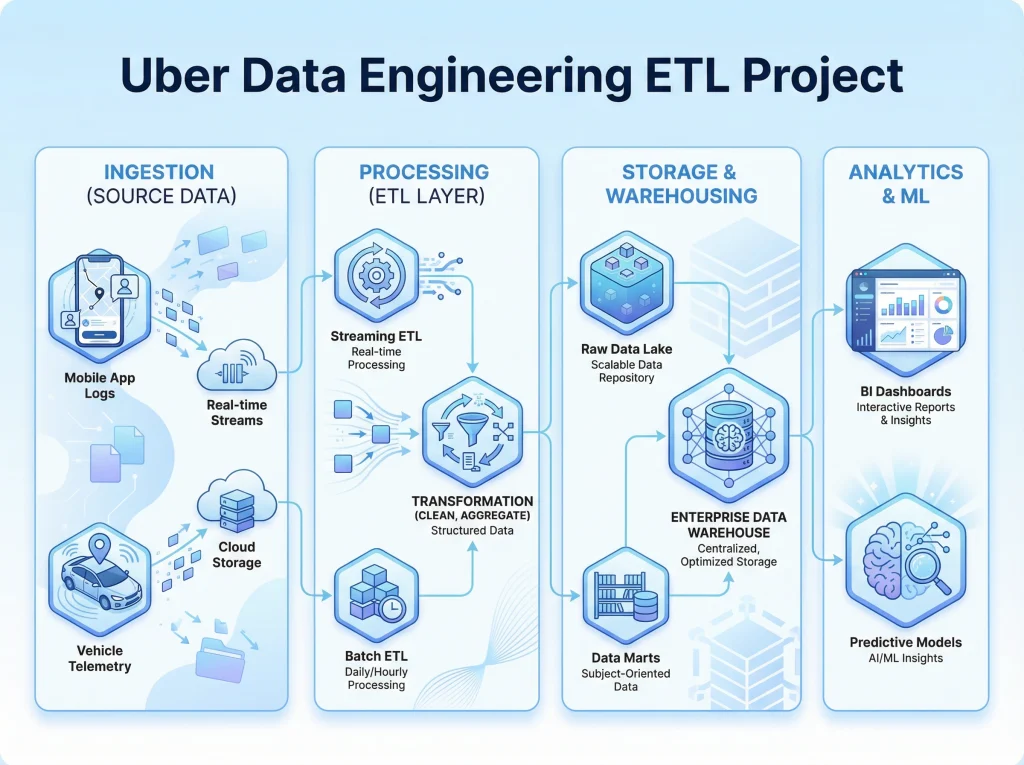
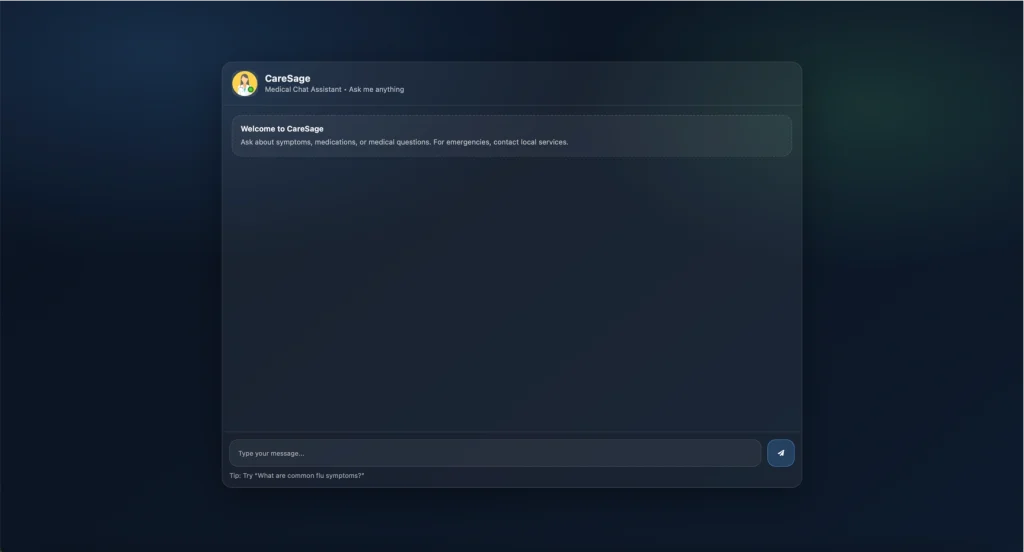
I specialize in building custom cloud and DevOps solutions for AI systems across healthcare, legal tech, e-commerce, SaaS, and other data-driven industries. My work combines cloud infrastructure, containerization, CI/CD, model deployment, observability, vector database hosting, and secure API operations to help businesses run AI products reliably at scale.
☁️ Cloud Infrastructure for AI
🐳 Containerization & Deployment
⚙️ CI/CD for AI Workflows
🚀 GPU Inference & Model Hosting
🔐 Security, Access & Monitoring
🧠 Vector Store & AI Backend Infrastructure

Key Metrics
Project Success Rate:
0
Trusted Clients:
0
Delivered Models:
0
Repeat Engagement:
0