
🎬 MovieMate — Personalized Movie Recommender
Content-Based Recommendation System with TF-IDF & Cosine Similarity
Machine Learning | Streamlit | TMDB API Integration
Project Overview
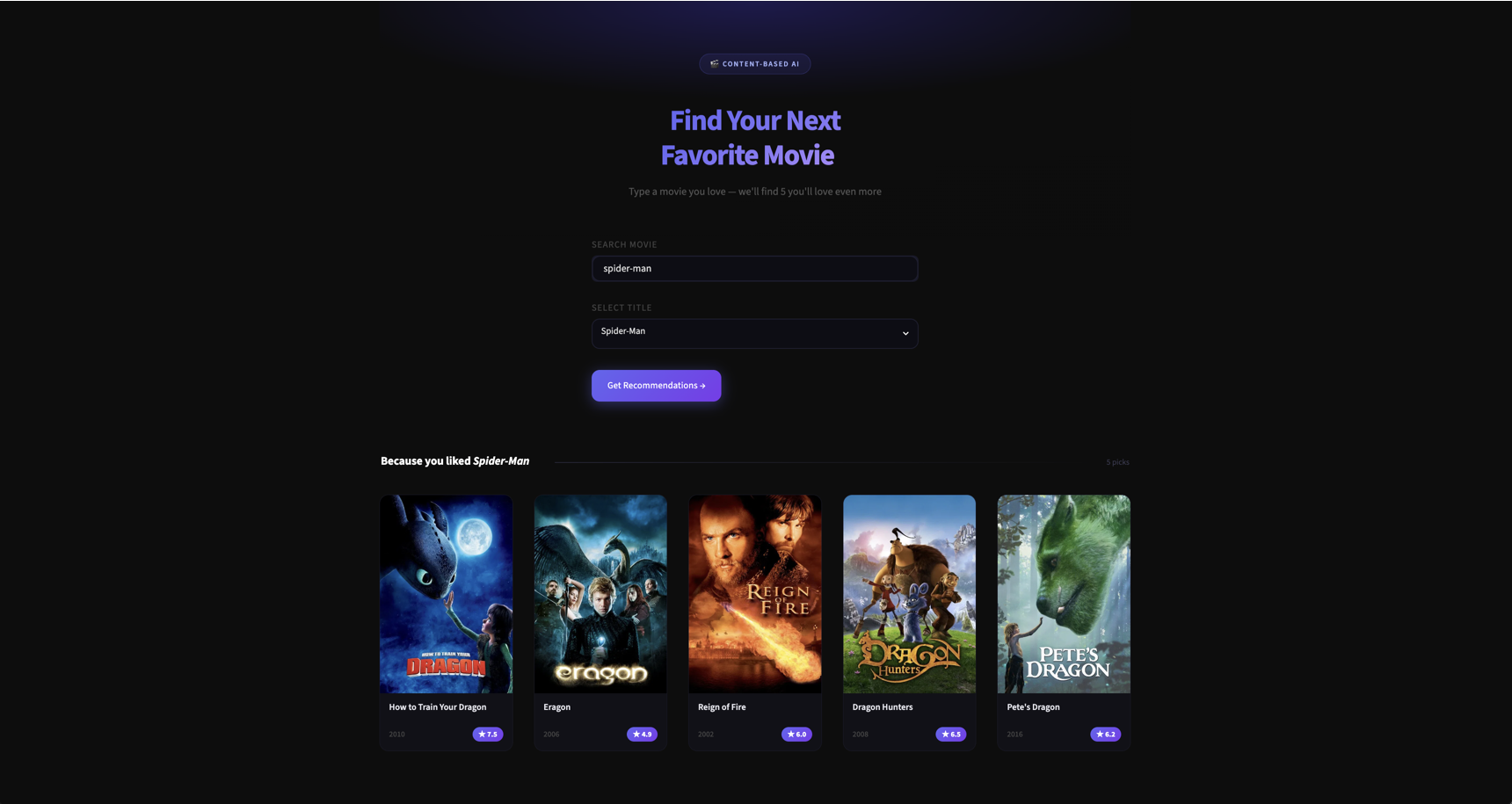
Built MovieMate, a personalized movie recommendation system that suggests 5 similar movies for any given title using content-based filtering on the TMDB 5000 movie dataset. The system analyzes movie attributes — genres, cast, crew, keywords, and overviews — to compute cosine similarity between films and surface intelligent recommendations.
The project is delivered as an interactive Streamlit web app with live poster fetching via the TMDB API, packaged with a clean modular structure (notebooks for EDA & training, src for production code, artifacts for serialized models) and ready for one-command deployment.
Recommendation Pipeline Architecture
🏗️ Content-Based Filtering
Approach: Movies are converted into feature vectors using TF-IDF on combined tags (genres + cast + crew + keywords + overview). Cosine similarity between vectors ranks the top 5 most similar films — scores range from 0 (no overlap) to 1 (identical).
Key Features & Capabilities
Personalized Recommendations
Suggests 5 highly relevant movies for any selected title from a catalog of 5000+ films, ranked by cosine similarity score.
TF-IDF Vectorization
Term Frequency–Inverse Document Frequency encoding converts movie metadata into meaningful numerical vectors for similarity computation.
Cosine Similarity Engine
Measures angular distance between movie vectors to rank films — robust to vector magnitude and ideal for sparse text features.
Live Poster Fetching
Real-time integration with the TMDB API to fetch and display movie posters alongside recommendations for a polished UX.
Streamlit Web Interface
Clean, interactive UI with movie search dropdown, one-click recommendations, and instant visual feedback with posters.
Pre-Computed Artifacts
Similarity matrix and processed movie data serialized as pickle files for instant inference without re-training at runtime.
Technical Implementation
📥 Data Processing & Feature Engineering
- Dataset: TMDB 5000 Movies & Credits dataset from Kaggle
- Feature Extraction: Parsed JSON-formatted columns (genres, cast, crew, keywords) into clean lists
- Tag Construction: Combined overview, genres, top cast, director, and keywords into a unified “tags” feature
- Text Cleaning: Lowercased, removed spaces in entity names, applied stemming with PorterStemmer
- Data Merging: Joined movies and credits datasets on title for complete metadata
🧠 Recommendation Algorithm
- Vectorization: TF-IDF / CountVectorizer with 5000 max features and English stop-word removal
- Similarity Computation: Pairwise cosine similarity matrix across all movie vectors
- Ranking Logic: Sort similarity scores per movie, return top 5 excluding the queried film
- Algorithm Type: Content-based filtering (no cold-start issues for new movies with metadata)
- Output: Top-N recommendations with movie titles and poster images
🎨 Frontend & API Integration
- Streamlit UI: Dropdown movie selector, recommend button, 5-column poster grid layout
- TMDB API: Fetches movie posters via movie_id with secure API key management
- Environment Variables: API keys stored in
.env.local(gitignored) with.env.exampletemplate - Error Handling: Graceful fallback for missing posters and failed API calls
- Modular Code: Separated recommender logic (
src/recommender.py) from UI (app.py)
🚀 Project Structure & Deployment
- Notebooks: EDA and model training in
notebooks/movie_recommender_analysis.ipynb - Artifacts: Serialized
movie_dict.pklandsimilarity.pklfor production use - Deployment Ready: Procfile + setup.sh for Heroku/Streamlit Cloud deployment
- Dependencies: Pinned in
requirements.txtfor reproducible builds - Licensing: MIT licensed for open use and contribution
Recommendation System Approaches
🎯 Content-Based ✅
Used in MovieMate. Recommends based on movie attributes — genres, cast, crew, keywords. No user data required, no cold-start for new movies.
👥 Collaborative Filtering
Recommends based on user-item interaction patterns and similarity between users. Powerful but requires interaction history.
🔀 Hybrid Systems
Combines content + collaborative approaches. Used in production by Netflix, Spotify, and Amazon for best-in-class personalization.